Формулировка: программные сущности (классы, модули, функции и т.д.) должны быть открыты для расширения, но закрыты для изменения
Какую цель мы преследуем, когда применяем этот принцип? Как известно программные проекты в течение свой жизни постоянно изменяются. Изменения могут возникнуть, например, из-за новых требований заказчика или пересмотра старых. В конечном итоге потребуется изменить код в соответствии с текущей ситуацией.
С одной стороны внесение изменений требует времени программистов и тестировщиков, которое является очень дорогим ресурсом в производстве ПО. С другой, бизнес должен достаточно быстро реагировать на рыночные изменения и время здесь представляется очень важным конкурентным преимуществом.
Отсюда можно сделать вывод, что нашей целью является разработка системы, которая будет достаточно просто и безболезненно меняться. Другими словами, система должна быть гибкой. Например, внесение изменений в библиотеку общую для 4х проектов не должно быть долгим («долгим» является разным промежутком времени для конкретной ситуации) и уж точно не должно вести к изменениям в этих 4х проектах.
Принцип открытости/закрытость как раз и дает понимание того, как оставаться достаточно гибкими в условиях постоянно меняющихся требований.
Примеры
Без абстракций
Проблема
Самый простой пример нарушения принципа открытости/закрытости – использование конкретных объектов без абстракций. Предположим, что у нас есть объект SmtpMailer. Для логирования своих действий он использует Logger, который записывает информацию в текстовые файлы.

public class Logger
{
public void Log(string logText)
{
// сохранить лог в файле
}
}
public class SmtpMailer
{
private readonly Logger logger;
public SmtpMailer()
{
logger = new Logger();
}
public void SendMessage(string message)
{
// отсылка сообщения
logger.Log(string.Format("Отправлено '{0}'", message));
}
}
И тоже самое происходит в других классах, которые используют Logger. Такая конструкция вполне жизнеспособна до тех, пока мы не решим записывать лог SmptMailer'a в базу данных. Для этого нам надо создать класс, который будет записывать все логи не в текстовый файл, а в базу данных:
public class DatabaseLogger
{
public void Log(string logText)
{
// сохранить лог в базе данных
}
}
А теперь самое интересное. Мы должны изменить класс SmptMailer из-за изменившегося бизнес-требования:
public class SmtpMailer
{
private readonly DatabaseLogger logger;
public SmtpMailer()
{
logger = new DatabaseLogger();
}
public void SendMessage(string message)
{
// отсылка сообщения
logger.Log(string.Format("Отправлено '{0}'", message));
}
}
Но ведь по принципу единственности ответственности не SmptMailer отвечает за логирование, почему изменения дошли и до него? Потому что нарушен наш принцип открытости/закрытости. SmptMailer не закрыт для модификации. Нам пришлось его изменить, чтобы поменять способ хранения его логов.
Решение
В данном случае защитить SmtpMailer поможет выделение абстракции. Пусть SmtpMailer зависит от интерфейса ILogger:

public interface ILogger
{
void Log(string logText);
}
public class Logger : ILogger
{
public void Log(string logText)
{
// сохранить лог в файле
}
}
public class DatabaseLogger : ILogger
{
public void Log(string logText)
{
// сохранить лог в базе данных
}
}
public class SmtpMailer
{
private readonly ILogger logger;
public SmtpMailer(ILogger logger)
{
this.logger = logger;
}
public void SendMessage(string message)
{
// отсылка сообщения
logger.Log(string.Format("Отправлено '{0}'", message));
}
}
Теперь смена логики логирования уже не будет вести к модификации SmtpMailer'а.
Проверка типа абстракции
Проблема
Этот пример в разных вариациях все не раз видели в коде. Его хоть в рамку можно вешать, как самое популярное нарушение проектирования. У нас есть иерархия объектов с абстрактным родительским классом AbstractEntity и класс Repository, который использует абстракцию. При этом вызывая метод Save у Repository мы строим логику в зависимости от типа входного параметра:

public abstract class AbstractEntity
{
}
public class AccountEntity : AbstractEntity
{
}
public class RoleEntity : AbstractEntity
{
}
public class Repository
{
public void Save(AbstractEntity entity)
{
if (entity is AccountEntity)
{
// специфические действия для AccountEntity
}
if (entity is RoleEntity)
{
// специфические действия для RoleEntity
}
}
}
Из кода видно, что объект Repository придется менять каждый раз, когда мы добавляем в иерархию объектов с базовым классом AbstractEntity новых наследников или удаляем существующих. Условные операторы будут множится в методе Save и тем самым усложнять его.
Решение
Конкретизируя классы методом is или typeof мы должны сразу понять, что наш код начал «попахивать». Чтобы решить данную проблему, необходимо логику сохранения конкретных классов из иерархии AbstractEntity вынести в конкретные классы Repository. Для этого мы должны выделить интерфейс IRepository и создать хранилища AccountRepository и RoleRepository:
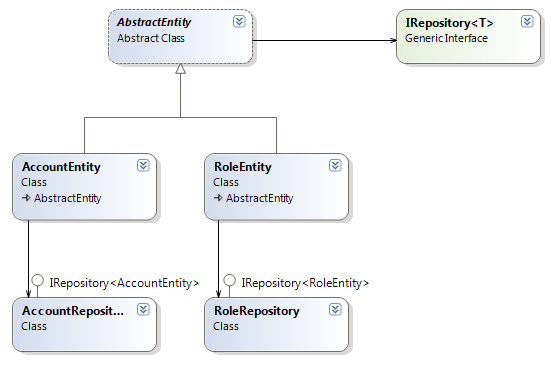
public abstract class AbstractEntity
{
}
public class AccountEntity : AbstractEntity
{
}
public class RoleEntity : AbstractEntity
{
}
public interface IRepository<T> where T : AbstractEntity
{
void Save(T entity);
}
public class AccountRepository : IRepository<AccountEntity>
{
public void Save(AccountEntity entity)
{
// специфические действия для AccountEntity
}
}
public class RoleRepository : IRepository<RoleEntity>
{
public void Save(RoleEntity abstractEntity)
{
// специфические действия для RoleEntity
}
}
Теперь наши изменения будут локализованы в конкретных объектах.
Этот пост входит в серию Принципы проектирования классов (S.O.L.I.D.):
- Принцип единственности ответственности (The Single Responsibility Principle)
- Принцип открытости/закрытости (The Open Closed Principle)
- Принцип замещения Лисков (The Liskov Substitution Principle)
- Принцип разделения интерфейса (The Interface Segregation Principle)
- Принцип инверсии зависимости (The Dependency Inversion Principle)
Ссылки
R. Martin: The Open-Closed Principle
К. Бек: The Open/Closed/Open Principle
спасибо!
ОтветитьУдалитьПрочитал, из статьи так и не понял, что значит "открыты для расширения" и "закрыты для изменения".
ОтветитьУдалитьВсе весьма понятно! Спасибо!!!
ОтветитьУдалить@hazzik
ОтветитьУдалитьСпасибо за вопрос, возможно многие его себе задали =)
Сейчас попробую совсем по-простому.
Ты хочешь расширять функциональность класса. Расширяя ее, тебе приходится изменять объект, что ведет к каскадным изменениям в системе. Значит, сам объект тебе менять не надо. А что можно в этой ситуации сделать?
Два варианта (http://en.wikipedia.org/wiki/Open/closed_principle)
1. Тебе надо выделить базовый объект из текущего класса и твоего будущего класса. Унаследовать текущий объект от созданного базового класса и использовать абстракцию. После этих преобразований система будет более устойчива к изменениям. Примеры есть в посте.
2. Унаследовать от текущего объекта твой новый объект и добавить в него необходимые (расширяющие) функции. Здесь надеюсь можно без примера.
Теперь понятно, спасибо, друг:)
ОтветитьУдалитьа уже существующие классы разве нельзя расширять доп. функциями, конечно с условием того, что на уже существующий код они влиять никак не будут?
ОтветитьУдалить@headachy
ОтветитьУдалитьХороший вопрос.
Конечно, можно! Если нет проблем, то не надо усложнять себе жизнь. Если возникает проблема
"...тебе приходится изменять объект, что ведет к каскадным изменениям в системе"
то уже тогда ищем пути решения =)
что то я недопонял с SmtpMailer - в первом случае экземпляр logger создавался в конструкторе, а во втором - передавался как параметрв конструктор. А теперь, если мне нужно хранить логи в базе, то в первом случае мне нужно всего то изменить код в конструкторе SmtpMailer, а во втором - найти все места в существующем коде, где я отправляю почту и изменить там параметр конструктора SmtpMailer - а это же куча классов. Так может, 1й вариант проще?
ОтветитьУдалить@Атрём
ОтветитьУдалитьВообще, суть этой замены заключается в том, что в дальнейшем нам уже не придется менять класс SmtpMailer из-за смены логирования. Мы сможем влиять на логирование извне. Например, наш проект, который будет использовать этот SmtpMailer сможет задать ему свои логгеры. К примеру, в проекте может быть несколько видов SmtpMailer'ов, которые используют разное логирование.
Если бы оставили DatabaseLogger внутри конструктора и не вынесли интерфейс, то SmtpMailer пришлось все равно каким-то образом настраивать в клиентском коде.
С другой стороны, если смены логирование происходят очень редко или вообще это был единственный случай, то можно и не выносить интерфейс в конструктор. Опять же от ситуации зависит.
Хмм.. есть интересное противоречие. Все "тяжелые" методологии типа RUP или CMMI четко устанавливают границы системы. Все требования более-менее детально прорабатываются. А раз так, то очевидно, что на стадии проектирования приложения вам не придет в голову мысль о том, что вам в дальнейшем придется менять механизм логирования (или, скажем, реализовывать поддержку оракла, если в концепции четко прописано ограничение в виде использования сиквел сервера). Логично?
ОтветитьУдалитьПисать код, который изначально заточен под расширяемость (это видно даже из приведенных примеров) существенно сложнее (больше объектов, сложнее связи между ними).
Закономерный вопрос: где золотая середина?
@ImageOfYou
ОтветитьУдалитьДа, вполне резонный вопрос =)
Мы используем XP, поэтому изменение требований заказчика и рефакторинг системы приняты как данность. Система должна быть изменена, если она не удовлетворяет текущим реалиям.
Возьмем первый пример. Изначально у нас есть Logger и SmptMailer. При этом все работает отлично. Не надо делать никаких лишний классов или интерфейсов. Как только нам пришлось внести изменения в SmtpMailer и мы поняли, что его изменения влекут каскадные изменения в нескольких местах системы, то надо вынести интерфейс и т.д...
Т.е. не надо изначально стремиться к самой-гибкой-гибкости-на-свете. Преждевременная оптимизация архитектуры может загубить эту самую архитектуру (чрезмерное кол-во объектов и т.п.) и снизить скорость работы команды (не решаем проблему, зато делаем расширяемую архитектуру).
Про "тяжелые" методологии сказать ничего не могу, потому что в реальных проектах с ними не сталкивался. Но думаю, что и там необходимо вносить изменения в систему, если какие-то проектные решения принятые вначале перестали работать к текущему моменту.
Вопрос по "Проверке типа абстракции".
ОтветитьУдалитьИзначально мы могли отдать экземпляру Repository любой объект типа AbstractEntity и он бы его сохранил независимо от конкретного сабтипа, а с интерфейсом IRepository как такое провернуть?
@dRn
ОтветитьУдалитьЯ правильно понял, что хочется оставить видимым один объект Repository и передавать ему AbstractEntity.
@Александр Бындю
ОтветитьУдалитьДа, но не допустить "попахивания" кода, т.е. избежать is или typeof. :)
@dRn
ОтветитьУдалитьВсе-таки создать конкретные Repository придется, о пусть это будут закрытые классы. Я могу предложить
использовать шаблон Registry (http://martinfowler.com/eaaCatalog/registry.html).
Видимый Repository будет принимать объект типа AbstractEntity. При этом он будет знать схему сопоставления
типа объекта и конкретного Repository, который умеет работать с объектами переданного типа. Сопоставление и
будет реализацией Registry
public class Repository
{
public void Save(AbstractEntity entity)
{
Registry.GetRepositoryFor(entity).Save(entity);
}
}
Само сопоставление реализуется очень просто:
public static class Registry
{
private static readonly Dictionary\Type, IRepository\ lookup = Init();
private static Dictionary\Type, Type\ Init()
{
return new Dictionary\Type, Type\
{
{typeof (AccountEntity), new AccountRepository()},
...
};
}
public static void GetRepositoryFor(AbstractEntity entity)
{
return lookup[entity.GetType()];
}
}
(угловые скобки заменены на \)
Вообще решения могут быть разными, это одно из возможных.
@ImageOfYou
ОтветитьУдалитьПосмотрите видео http://www.it4business.ru/video/2025/ и вы поймете, почему RUP и ему подобные MSFы не для нас.
Заказчику не нужен проект, удовлетворяющий ТЗ, ему нужен проект, который удовлетворяет его требованиям, а его требования могут меняться :) Кататак.
Спасибо, очень познавательно. А чем такие диаграммы нынче рисуют?
ОтветитьУдалить@ucme
ОтветитьУдалитьЭти я делал стандартными средствами Visual Studio.
спасибо за отличную статью! У меня возник вопрос по первому премеру: всегда ли нужно определять абстракции для конкретных объектов? (или только в случае возможного изменения объекта)
ОтветитьУдалить@Алексей
ОтветитьУдалитьНа этот счет нет правила или формулы. Я бы посоветовал создавать интерфейсы для общения между сборками, а делать внутри сборок абстрактный класс или не публичные интерфейсы, это уже зависит от конкретного случая.
Если у вас есть как-то пример для разбора, то присылайте.
С принципом закрытости все понятно - берем находим в классе1 то что изменяется инкапсулируем эту изменяемую логику в отдельный класс2 или интерфейс тем самым изолируем класс1 от изменений.
ОтветитьУдалитьА что такое "Принцип открытости"? как можно нарушить этот принцип?
@Avl
ОтветитьУдалитьПосмотрите в формулировку. "...открыты для расширения, но закрыты для изменения".
Отсюда открытость для расширения, а закрытость для изменения.
В примере с Logger - я бы перенёс разветвление в класс Logger, использовать приватное поле ILogger, которое инициализируется конкретным вариантом в констукторе, в Logger.Log() просто перенаправляет вывод на ILogger.
ОтветитьУдалитьЭто централизованное управление политикой глобального логгирования.
@sham-bho
ОтветитьУдалитьПроблема будет, если этот 'централизованный' Logger надо будет изменить извне, к сожалению он получится нерасширяемым.
Преимущество разных классов, реализующих ILogger в том, что 1) я могу использовать в одном приложение разные логгеры в зависимости от контекста (настраивается в IoC-контейнере) 2) могу взять библиотеку, где есть SmtpMailer и передать в нее свой логгер, которого не было изначально у автора библиотеки.
Если надо, могу для примера накидать код.
Наверно сначала надо определиться с политикой логгирования, потом уже проектировать архитектуру логгирования. Использование разных вариантов ILogger я бы заменил на категории источника лога, которые направляют лог на централизованный менеджер лога, который в свою очередь распределяет логи уже по реализациям (ILogger в вашем примере). А маппинг категорий логирования на реализации логирования производится централизованно через менеджер лога где-то в одном месте программы. Вроде примерно так и реализованы библиотеки логирования в Java и .Net
ОтветитьУдалитьКласс (лучше даже статический) Log же пусть будет просто обёрткой - если в проекте изменится библиотека логгирования, это не затронет клиентов логирования.
т.е. в Вашем случае: использовать SmtpMailer с DatabaseLogger,
ОтветитьУдалитья предлагаю: использовать SmtpMailer с SmtpMailerLogSource, а где-то в другом месте программы задать отображение: перенаправлять лог с SmtpMailerLogSource на DatabaseLogger.
@sham-bho
ОтветитьУдалитьЯ понял вашу идею.
Обратите внимание, что если пример оторвать от какой-то специфики, в данном случае логирование, то он показывает суть принципа проектирования.
Концепция, которую вы предложили, я считаю через чур усложненной, но если вдруг в вашем проекте надо было именно так, что значит она имеет право на жизнь.
По-моему мнениею логирование проще всего настроить одной строчкой в IoC-контейнере, чем делать дополнительную абстракцию и статический класс.
Да, каркас логирования сложен, но он реализован в библиотеке один раз (зачастую - поставляемой с платформой разработки). А настроить логирование парой строчек можно и здесь:
ОтветитьУдалитьclass SmtpMailer {
LogSource log = new SmtpMailerLogSource();
...
}
...
// настраивается примерно так,
// с точностью до библиотеки логирования
// и GoF.Facade для неё:
LogManager.мap(StmpMailerLogSource.id,
DatabaseLogger.id, FileLogger.id);
Это более гибкий подход, можно централизованно задавать отображение вывода на несколько логгеров.
Ну это мы уже ушли в дебри, не имеющие отношение к иллюстрации принципа OCP.
Как пример исправления нарушения принципа - вполне устраивает.
@sham-bho
ОтветитьУдалитьСпасибо, что обратили внимание на этот нюанс, раньше не замечал.
Мне очень интересно в каком редакторе вы рисовали UML схемы.
ОтветитьУдалитьВстроенный в VS
ОтветитьУдалитьКак и написано, примеры исправлены, потому что нарушается SRP и DIP. Как нарушить OCP, если при этом SRP и DIP выполняются? Или SOLID не базис?
ОтветитьУдалитьХочу лишь кинуть свои копеек
ОтветитьУдалитьПочему нужны абстракции в данном примере?
Потому что OCP предполагает:
Открыт для расширения - закрыт для модификации, вроде как противоречит друг другу, но если мы возмём абстаркцию которая как-бы фиксированная (закрыт для модификации) - поведение её можно изменять с помощью переопределения (открыт для расширения). Так эти два понятия "уживаются" вместе. Мысля взята из книги Мартина.
А как все таки быть с ситуацией подобной последней в языке C++, когда у нас нет метода GetType() для создания Registry и мы не хотим, чтобы Entity что-либо знала о Repository?
ОтветитьУдалитьСамый простой способ добавить стратегию для сохранения сущности и передавать ее в репозиторий.
ОтветитьУдалитьНе совсем понял, как это поможет. Можешь привести пример кода, пожалуйста (не обязательно на C++) Задача не гипотетическая, я с ней действительно столкнулся пару дней назад, потому очень интересно разобраться в ее решении
ОтветитьУдалитьSave(AbstractEntity entity, ISaveStrategy strategy)
ОтветитьУдалить{
// обычное сохранение
strategy.Apply();
}
Спасибо, но все же опять что-то осталось за кадром. Откуда берется соответствие между конкретной entity и конкретной SaveStrategy? Если перед вызовом метода save(...) стоит if, то зачем это все вообще городить? Или перед вызовом метода save(...) словарик с соответствием каждого объекта сущности каждой конкретной стратегии сохранения?
ОтветитьУдалитьВопрос какую стратегию передавать можно решить разными способами. Несколько вариантов вы перечислили, но самый красивый будет, если сделать фабрику стратегий и выбирать нужную с помощью IoC.
ОтветитьУдалитьВы можете посмотреть http://docs.castleproject.org/Windsor.Typed-Factory-Facility-interface-based-factories.ashx и пример, как это сделать в https://github.com/AlexanderByndyu/ByndyuSoft.Infrastructure/blob/master/samples/aspnetmvc/src/Web/Installers/FormHandlerInstaller.cs
Отличная статья, но есть вопрос. Получается, что вместо одного IF нам надо создать два класса и дополнительный интерфейс, а что если будет 10 классов, тогда один case придеться заменить на 10 классов или я что то не допонял?
ОтветитьУдалитьСпасибо за вопрос. Суть в том, что мы не должны делать проверки на типы или даункасты. Это приводит к тому, что класс, который проверяет абстракцию на тип, становится зависим от конкретной реализации этой абстракции. В этом случае вся суть абстракции теряет свою ценность.
ОтветитьУдалитьДобавить интерфейс или не добавлять значения не имеет, я показал одну из реализаций. Ее суть сводится к замене условной логики на полиморфизм. Это стандартный рефакторинг, примеры можно поискать по запросу "replace conditional with polymorphism"
Александр, а можно философский вопрос: а почему Вы считаете, что конкретный класс не является абстракцией?
ОтветитьУдалитьМне всегда казалось, что абстракция невозможна без инкапсуляции, но вполне возможна без наследования. Так, например, StringBuilder - это абстракция: она говорит, что строит строку, при этом не говорит, как именно. Сам класс String - это абстракция, она моделирует строку в определенной кодировке, при этом нас не интересует, является ли она null-termniated или нет.
Наследование добавляет еще один потенциальный уровень косвенности и может позволить заменять поведение во время исполнения, если мы будем использовать агрегацию вместо композиции. Но это ведь ортогональные вещи.
Есть же формальные определения понятия абстракции, и я нигде не видел, чтобы приравнивали абстракцию с наличием интерфейса или абстрактного базового класса.
Сергей, давно я писал эти статьи :) А где в тексте промелькнуло, что конкретный класс не является абстракцией? Может я просто мало примеров привел.
ОтветитьУдалитьМеня смутила вот эта фраза:
ОтветитьУдалить"Самый простой пример нарушения принципа открытости/закрытости – использование конкретных объектов без абстракций.".
И я сделал вывод, что конкретный класс не является абстракцией.
Сергей, надо бы подумать, что же я тут имел ввиду :)
ОтветитьУдалитьЕсли воспринимать эту фразу буквально, то получается, что для любого класса нужна абстракция. В целом это далеко от практики и здравого смысла.
Я думаю более "современная" трактовка должна предполагать, что для Stable
Dependencies абстракции не нужны, а для Volatile Dependencies стоит добавить слой абстракции.
Спасибо, мне нравятся такие хорошие примеры, как этот - http://plutov.by/category/php
ОтветитьУдалить