Последние 2 года большая часть проектов моей компании - это унаследованные системы. Я уже писал, что это за системы, какие риски возникают при работе с такими системами и каким образом проводится анализ. Интересно, что все эти системы имели монолитную архитектуру, которая была основной проблемой на пути к горизонтальному масштабированию. Для меня было вопросом как и почему получается монолитная архитектура? Как избежать такого подхода?
Описанные ниже проблемы и способы решения не являются исчерпывающим руководством по переходу к распределенной архитектуре. Скорее, это перечисление шагов и практик, которые пригодились на наших проектах и привели к нужным результатам.
Для тех, кто любит смотреть, а не читать, предлагаю видео и слайды с очень близким содержанием. Также на видео есть много вопросов-ответов, которые у вас могут возникнуть.
Если вам больше нравится читать, то ниже статья.
Теорема CAP
Теорема CAP говорит нам, что для распределенной системы невозможно реализовать все 3 свойства одновременно, придется выбирать два из трёх:
- Consistency (согласованность данных)
- Availability (доступность)
- Partition tolerance (устойчивость к разделению)
У этой теоремы нет строго доказательства и есть противники, но она нужна нам для понимания ограничений, с которыми мы сталкиваемся в повседневной практике.
Итак, выбираем любые два свойства для нашей системы и получаем комбинации:
- Consistency + Availability
- Consistency + Partition tolerance
- Availability + Partition tolerance
Нам будут интересны 1-й и 3-й пункты. Первый пункт - это типовые решения, которые сейчас преобладают на рынке. 3-й пункт - это NoSQL решения, которые сейчас набирают популярность. Интересно, что создатели NoSQL решений ссылаются на CAP теорему, когда говорят о невозможности реализовать Consistency в своих системах. Availability + Partition tolerance - легко, но вот консистентности данных вы не получите.
Consistency + Availability и последствия
Как мы обычно реализуем проекты? Есть набор слоев, которые общаются друг с другом:

У каждого слоя свои очевидные цели и задачи. Такому подходу все обучены и каждый применял его в большинстве своих проектов.
По мере развития проекта добавляются новые подсистемы: веб-сервисы, анализаторы данных и т.п. Все подсистемы, построенные по единому шаблону, приводят архитектуру проекта к Shared DB:

Основной связующий узел - БД в центре проекта. Через неё идёт вся коммуникация, она же является общим хранилищем данных.
Чем хорош такой подход? Все подсистемы проекта работают с последними версиями данных, данные консистентны в масштабах всего проекта. От такой архитектуры возникает чувство надежности, предсказуемости и защищенности. И самое главное - этот подход понятен почти любому разработчику, даже вчерашнему студенту.
Проблемы с масштабированием
Подход описанный выше работает при решении типовых задач. Проблемы начинаются со временем, когда БД вырастает до сотен гигабайт, когда появляется много желающих считать и записать данные в БД.
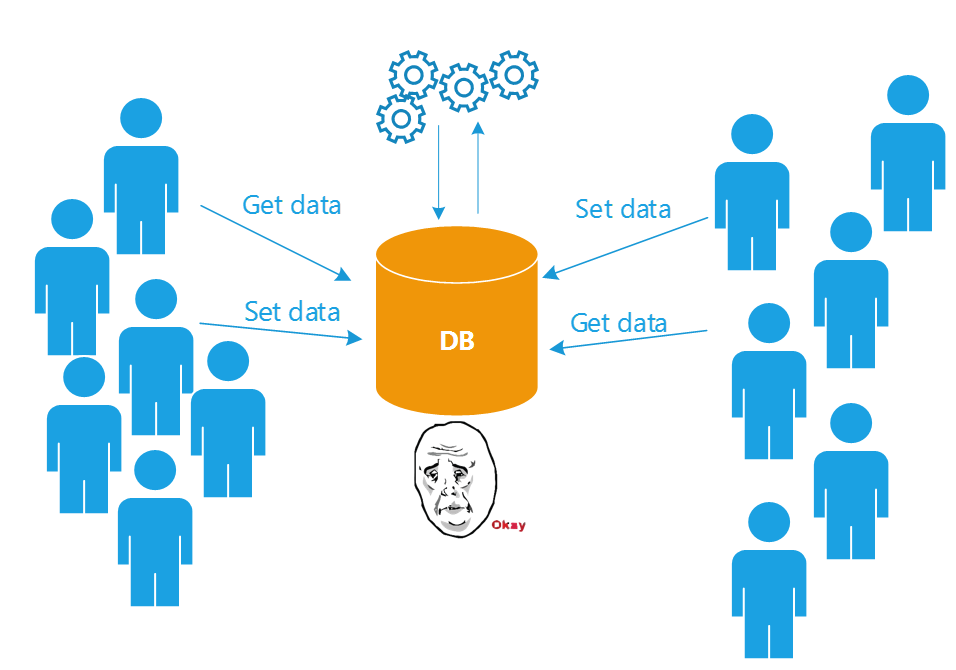
БД перестает справляться с потоком транзакций от всех подсистем, начинаются блокировки и задержки с откликом. Какое самое простое решение проблемы? Вертикальное масштабирование, т.е. докупание железа. Давайте купим сервер помощнее!
У вертикального масштабирования, к сожалению, есть потолок роста. После покупки очередного сервера с 2 ТБ SSD-дисков вы начитаете задумываться, может что-то надо менять в архитектуре?

Вот на этот вопрос я и хочу написать примеры наших решений, зарекомендовавших себя на практике. Решения условно разделим на горизонтальное масштабирование чтения данных и записи данных.
Масштабируем нагрузку на чтение
Многие системы отдают данные на порядок больше, чем изменяют их. Возьмем для примера любой блог или ленту новостей. Новости добавлются довольно редко, зато запросы на просмотр новостей идут очень часто. Поэтому первое, что хочется сделать для оптимизации нагрузки - понять как горизонтально масштабировать нагрузку на чтение. В идеале, делать это в пару кликов или вообще автоматически.
Представьте себе, что ваша система медленно отдает данные. Задержки уже превышают 20-30 секунд и пользователи негодуют. Типовые приёмы, к которым прибегают разработчики в этих случаях:
- Оптимизировать скрипты выборки - попытка узнать больше о хинтах и других возможностях тонкой настройки запроса.
- Убираем ORM для лучшей оптимизации - сами ORM редко делают оптимальные запросы, а сложный запрос написать на языке понятном ORM (Linq, HQL и т.п.) практически невозможно. Пример из практики Dapper + QueryObject, как замена ORM
- Убираем весь код выборки в хранимые поцедуры - есть мнение, что таким образом SQL-код начинает работать быстрее.
- Оптимизируем индексы - бывает, что индексов в БД вообще нет, тогда их стоит постоить. Если они уже построены, то есть способы их тюнинга.
- Денормализуем данные - когда все возможности исчерпаны, то этот способ является самым действенным.
Денормализация данных
В первые месяцы моей работы программистом, 7 лет назад директор по развитию компании рассказал мне эту байку. В тот момент я не понял о чем речь, зато сейчас проникся очень глубоко. Эволюция наших знаний о базах данных:
- Сначала мы ничего не знаем о БД и храним данные как попало
- Дальше мы узнаем о нормализации, начинаем проектировать БД с учетом нормальных форм
- В итоге, мы понимаем, что идеальная БД, созданная с учетом всех нормальных форм, не жизнеспособна. Мы учимся как данные правильно денормализировать, чтобы выборки работали быстро.
Денормализация v1.0
Что больше всего тормозит SQL-запрос? Скорее всего оператор JOIN, когда приходится объединять много таблиц и записей. Как показала практика, если в JOIN участует по миллиону строк из каждой таблицы, такой запрос работать быстро не будет никогда, даже при самых глубоких оптимизациях.
Возьмем для демонстрации простой пример с таблицами Products и ProductType. Надо выбрать код продукта по ProductID:
SELECT pt.Code FROM Products p INNER JOIN ProductType pt ON p.ProductTypeID = pt.ProductTypeID WHERE p.ProductID = 20
Чтобы избавится от JOIN, надо в существующей таблице Products создать колонку Code и скопировать туда данные из таблицы ProductType. Получим запрос, который гораздо легче предыдущего:
SELECT p.Code FROM Products p WHERE p.ProductID = 20
С точки зрения ускорения выборки, такой способ денормализации решает простые проблемы. Недостаток в том, что к существующим таблицам мы добавляем дублирующие колонки. Кроме того, нужны дополнительные усилия на поддержание консистентности поля Code в двух таблицах.
Денормализация v2.0
Когда первый способ денормализации уже не спасает, тогда переходят к тяжелой артиллерии. Под каждый тяжелый запрос создается отдельная таблица, вьюха, материализованное представление или что там есть в вашей СУБД. Эта сущность содержит только колонки, которые надо выбрать, ничего лишнего, никаких JOIN-ов, никаких внешних ключей и constraint'ов.
Например, для выборки данных из таблиц Orders и Products можно сделать View только с нужными колонками custID, orderDate, UPC:

SELECT opd.orderDate, opd.UPC FROM OrderProductDenormalized opd WHERE opd.custID = 20
Выборка по специально подготовленной View пойдет очень быстро с минимальной загрузкой жесткого диска и других ресурсов сервера.
Этот способ может решить часть проблем. Он разгружает основные таблицы БД, теперь в них возникает меньше блокировок. С другой стороны, нужны дополнительные усилия на поддержание консистентности View, ее надо периодически перестраивать.
Проблема не решается кардинально, т.к. в денормализациями v1.0 и v2.0 мы нагружаем тот же сервер БД, а его хочется разгрузить или распределить его нагрузку по большому количеству дешевых серверов.
Есть еще способы с репликацией БД и чтением данных из реплик, но я не буду их рассматривать.
Денормализация v3.0
А кардинальное решение с загрузкой сервера БД есть. Нужно создать еще одну БД, а точнее хранилище, не обязательно БД, c «плоскими» данными для чтения. Возможные варианты:
- Отдельная реляционная БД с «плоскими» данными без связей. Типовой пример из практики Integration Patterns: Репликация и очередь сообщений
- Различные NoSQL-решения
- Поисковые движки
- Кэш
- ...
К этому придёт большинство проектов, которые имеют нагрузку на чтение данных. Дальше мы детально рассмотрим этот подход.
Схемы архитектуры сильно упрощены, вопросы по деталям реализации предлагаю выносить в комментарии
CRUD неоднородный
Из CRUD операций в данный момент мы думаем, что делать с R и как это повлияет на архитектуру системы. Выше было решено сделать одни хранилища для записи данных, а другие специально заточить под чтение.
cRud
Когда дело доходит до анализа данных, то оказывается, что типовой способ хранения не подходит, данные должны быть подготовлены к быстрой выборке с другой схемой и другими способами чтения. Чтение данных из специально подготовленного хранилища должно идти напрямую из UI (например, из контроллера) с созданием DTO (ViewModel) сразу под отображение данных:

Подробнее об этом предлагаю прочитать в статье Reporting Database Мартина Фаулера.
Приведу несколько примеров. Для оторажения сложного графика мы можем предварительно насчитать данные или сделать "плоскую" таблицу со сводными данными, из которой простым запросом можно сделать график. Для отображения рекомендаций пользователю мы можем заранее проанализировать данные и подготовить список рекомендуемых книг, этот список будет периодически обновляться.
CrUD
Часть системы, где мы меняем данные, остается без изменения:
- Domain-driven design (DDD)
- N- tier, onion,… architecture
- ORM (NHibernate, Entity Framework,…)

Итого получаем разделение нашей архитектуры на запись и чтение данных:

Здесь есть отсылка к CQRS, эта тема подробно рассмотрена в статье Command and Query Responsibility Segregation (CQRS) на практике.
Горизонтальное масштабирование
Где же долгожданное горизонтальное масштабирование нагрузки на чтение данных? И масштабирование в пару кликов мышкой? Обратите внимание на список продуктов, которые предлагается использовать для чтения. Это всё NoSQL-решения, которые прекрасно масштабируются на множество нодов, причем каждый нод может быть дешевым сервером.

На практике мы используем облачную инфрастуктуру от AWS и Azure. Создание дополнительных нодов занимаем пару кликов. Например, вы используете ElasticSearch и два текущих сервера не справляются, что делать? Накликаем еще 5-6 серверов, индекс перераспределиться по ним и дело сделано, наша система теперь может выдержать больше запросов на чтение.
Теперь вспомните про SharedDB, которую мы рассматривали в начале статьи, и подумайте, сколько кликов вам надо сделать, чтобы там смасштабировать нагрузку на чтение?
Синхронизация хранилищ
С решением по горизонтальному масштабированию на чтение мы определились, но остался один незакрытый вопрос. Если данные изменяются в одной БД, а читаются из другого хранилища, то как эти данные синхронизируются между БД и хранилищем?

Есть 2 принципиальных способа. Можно обновлять данные синхронно, т.е. при изменении данных в части записи сразу обновлять их в хранилищах для чтения.

У этого способа есть ряд недостатков:
- Замедляется скорость работы верхней части системы, отвечающей за изменение данных
- Данные нужно преобразовывать при отравке в хранилища для чтения. Код преобразования будет копиться в верхней части, где он не нужен. Так же будут копиться зависимости от драйверов для этих хранилищ.
Второй способ асинхронный - сихнронизация через очередь сообщений:

При изменении данных, формируется сообщение с набором изменений и отправляется в очередь. На стороне приемника данные преобразуются и заносятся в хранилища для чтения. Мы полностью разгружаем отправителя и можем просто масштабировать приемников сообщения, за счет очереди.
У такого подхода тоже есть недостатки:
- Данные попадают в хранилище для чтения не сразу. Другими словами пользотель не сразу увидит изменения, а через какое-то время. Консистентность данных на уровне всей системы достигается со временем, это называется Eventually Consistent
- Через какое гарантированное время данные дойдут до места их чтения? Придется искать ответ на этот вопрос
- В целом архитектура становится сложной, гораздо сложнее варианта с SharedDB
- Обработка ошибок становится нетривиальной задачей. Что делать, если сообщение с изменением данных ушло, но при обработке произошла ошибка?
- В ходе переброса и преобразования данных возможны потери, поэтому для начала надо обосновать Eventually Consistent. Уверены ли вы, что консистентность когда-то будет достигнута?
При всех сложностях этот способ очень популярен, т.к. дает почти безграничную горизонтальную масштабируемость.
На практике используются оба способа синхронизации. Первый способ обычно хорошо подходит для работы с кэшами, а второй для заполнения NoSQL-решений и плоских таблиц в реляционных базах.
Уход от реляционных СУБД
В схемах выше мы видим, что для части записи используется реляционная СУБД, но это не является обязательным. С таким же успехом для части с записью (богатой бизнес-логикой) можно использовать NoSQL-решения:

При таком подходе мы будем, например, сохранять корни агрегатов в JSON. Похоже, что и чтение и запись могут отлично масштабироваться. Но, как всегда, есть одно "но". Расскажу случай из практики.
Нам передали на разработку проект, где всё работало на Couchbase. Разработчики выбрали это решение, т.к. у Couchbase хорошая скорость на вставку, удобное администрирование и простое масштабирование. В чем же тогда проблема?
Как делается выборка данных из Couchbase и подобных систем? Вы пишите функции Map и Reduce, которые собирают данные со всех нодов и дают вам результат. В Couchbase вы пишите MapReduce для View (для простоты можно представить View, как индекс с данными). Когда вы делаете вставку данных по ключу, то эти данные не сразу попадают во View (помните про Eventually Consistent?), а через какое-то время.
Сценарий работы администратора с проблемой: администратор добавляет новость, идет в ленту новостей, не видит добавленную новость. Идет в админку, добавляет новость еще раз, идет в ленту, не видит добавленную новость... Так повторяется несколько раз. Проходит 5-10 минут, вставленные в Couchbase ключи индексируются во View, в ленте появляется 10 одинаковых новостей.
Проблема была в том, что админка - это в чистом виде CrUD операции и UX для них должен был быть соответствующий. Пользователи не знают и не хотят знать про Eventually Consistent. Их надо как минимум предупредить о таком своействе системы.
Но решение проблемы оказалось еще более обескураживающим. Разработчики в цикле посылали во View запрос с флагом stale=false (принудительно обновление индекса), до тех пор, пока View не обновлялась. Это, конечно, негативно влияло на загрузку сервера.
Отсюда надо сделать вывод, что каждый инструмент хорошо в своих границах и нужно знать о свойствах разных инструментов, чтобы сделать обоснованный выбор.
Масштабируем нагрузку на запись
Запись горизонтально масштабируется хуже, чем чтение, но некоторые приемы у нас есть. Обратите внимание на то, как в Shared DB идет обмен данными между различными подсистемами:

Если у вас подобная схема, то задумайтесь о том, чтобы убрать обмен данными в очередь сообщений:

За счет этого вы уберете лишнии записи и чтения в БД. Подробно переход к очереди я уже описыл в статье Integration Patterns: Shared DB, state machine и очередь сообщений, сейчас не буду повторяться.
Почему это важно?
Делать или не делать возможность для горизонтального масштабирования зависит от деталей вашего проекта и требований рынка. Что сейчас требуется от программных решений:
- Работа с большими объемами данных - для нас от 500 ГБ и таблицы от 100-150 млн. записей уже считаются большим объемом. С таким количеством записей уже не получится сделать неоптимальный запрос.
- Работа с нагрузками - либо от пользователей (примерно от 100 запросов в секунду к вашим серверам заставят вас задуматься об оптимизации запросов и скорости отклика), либо от внутренних сервисов. Например, 10 млн. сообщений в день проходит по очередям сообщений.
- Быстрое масштабирование - в идеале масштабирование любой подсистемы должно происходить в несколько кликов мышкой.
- Быстрое внесение изменений - никто не хочет ждать даже месяц, прежде чем получит новые функции. Итерации в одну неделю тоже можно считать длинными. Поставка инкремента продукта должна быть возможна несколько раз в неделю. Если ваш проект не умеет масштабироваться, то сколько будет ждать заказчик, пока вы переделаете архитектуру?
Шаги, которые проходят наши проекты очень похожи и описаны выше. Надеюсь, что их описание сэкономит вам время на выработку и внедрение решений.
Разбор примеров
На конференции SECON'14 в Пензе после доклада на эту тему был баркемп:

На нем мы разобрали несколько примеров с проблемными архитектурами. Любой мог подойти, нарисовать свою архитектуру и спросить куда идти дальше. Все участники давали очень ценные советы. Да и сами спрашивающие находили решения, пока рисовали, такой "эффект желтой уточки".
Если у вас есть проблемы или вопросы по вашей архитектуре, то предлагаю обсуждать в комментариях или пишите мне на почту.
Кроме того, вы можете заказать у меня анализ архитектуры вашей системы.
Ссылки
Eventually Consistent – Revisited, Werner Vogels
If You Have Too Much Data, then 'Good Enough' Is Good Enough, Pat Helland
Ошибки в системах баз данных, согласованность "в конечном счете" и теорема CAP, Майкл Стоунбрейкер
BASE: An Acid Alternative, Dan Pritchett
Micro-services архитектуры - избавляемся от монолитного кода, Ринат Абдуллин

Спасибо за хорошую статью.
ОтветитьУдалитьОт себя добавлю что исходя из CAP теоремы, CP решения возможны. Например, Couchbase, Cassandra (с определенными настройками ConsistencyLevel), Aerospike и прочие. Вообщем-то, в любой p2p master-less базе данных есть возможность получить нужный уровень консистентности. И в большинстве из них - консистентность выбирается на каждый запрос. Соответственно, появляется возможность выбирать где важна скорость, а где консистентность.
Антон, спасибо за дополнение.
ОтветитьУдалитьВ CAP-теореме, "P" не выбирается. Разделения есть и будут, весь вопрос в том, чем система пожертвует - C или A.
ОтветитьУдалитьТ.е., "типичное" решение (СУБД на одном сервере) - это CP, а не CA, так как при отделении приложения от СУБД или клиентов от приложения система в целом перестает приниматься запросы (т.е., жертвует A в угоду C).
ОтветитьУдалитьКонечно, это терминологичекие вопросы, но все же.
Под устойчивостью к разделению сети (P) понимают способность системы работать при потере произвольного числа сообщений, посылаемых из одного узла системы в другой (http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.67.6951&rep=rep1&type=pdf). Речь не идет об отключении клиента, т.к. остальные свойства (прежде всего A) понимаются в терминах "на каждый запрос, полученный не отказавшим узлом". Если у нас вырожденный случай - монолитная система, состоящая из одного узла, содержащего сервер приложений и СУБД, то P можно пренебречь - узел не может оделиться от самого себя. А интересны эти рассуждения потому что такие большие монолитные системы в мире есть и успешно эксплуатируются.
ОтветитьУдалитьДругое дело, что у Александра на схеме показано подключение нескольких серверов к СУБД и возможно по сети, здесь действительно стоило бы дать какие-то комментарии.
Если ссылка битая, поищите вот это: Seth Gilbert, Nancy Lynch. Brewer's conjecture and the feasibility of consistent, available, partition-tolerant web services. ACM SIGACT News, Volume 33 Issue 2, June 2002, pp. 51-59.
ОтветитьУдалить